
Bạn quan tâm đến việc thực hiện phân tích thống kê suy diễn trong SPSS? Bài viết này sẽ hướng dẫn bạn qua từng bước thực hiện thông qua ví dụ minh họa và phân tích kết quả chi tiết. Bạn sẽ khám phá cách áp dụng phân tích này trong các tình huống thực tế và làm thế nào để sử dụng mô hình để đưa ra dự đoán chính xác. Đừng bỏ lỡ cơ hội nâng cao kỹ năng phân tích dữ liệu của bạn cùng Luận văn Việt!

1. Thống kê suy diễn là gì?
Thống kê suy diễn (Inferential statistics) là quá trình sử dụng phép toán thống kê để đánh giá thông tin mô tả từ dữ liệu mẫu, nhằm xác định tính đáng tin cậy của thông tin này bằng cách kiểm chứng các giả thuyết. Các giả thuyết liên quan đến các tham số của toàn bộ quần thể được gọi là giả thuyết thống kê. Thống kê suy diễn giúp chúng ta kết luận xem giả thuyết đó có thể được chấp nhận hay phải bác bỏ.
Mục tiêu chính của thống kê suy diễn là tìm hiểu và khám phá những đặc trưng cơ bản hoặc quy luật ẩn sau nội dung nghiên cứu dựa trên dữ liệu mẫu, với tư duy về sự biểu diễn của thông tin trên một quy mô lớn hơn. Thống kê suy diễn thường được áp dụng khi chúng ta cần tổng hợp thông tin từ dữ liệu mẫu, ví dụ như trong lĩnh vực lương học, dân số học, và nhiều lĩnh vực thống kê khác, để ước tính các thông số quan trọng của toàn bộ quần thể.
2. Thống kê suy diễn SPSS là gì?
Trong SPSS (Statistical Package for the Social Sciences), thống kê suy diễn được sử dụng để thực hiện các phân tích và kiểm định thống kê có mục tiêu là xác định tính đáng tin cậy của các kết quả dựa trên dữ liệu mẫu và áp dụng chúng cho toàn bộ quần thể hoặc dân số. SPSS cung cấp nhiều công cụ và phương pháp thống kê suy diễn khác nhau, bao gồm:
- Kiểm định t: Dùng để so sánh trung bình của hai mẫu hoặc kiểm định trung bình của một mẫu so với một giá trị chuẩn.
- Phân tích phương sai (ANOVA): Dùng để so sánh trung bình của ba hoặc nhiều mẫu khác nhau để xem xét xem có sự khác biệt đáng kể giữa chúng hay không.
- Hồi quy: Sử dụng để xác định mối quan hệ giữa một biến phụ thuộc và các biến độc lập.
- Phân tích hồi quy logistic: Sử dụng để dự đoán xác suất của biến phụ thuộc là một biến nhị phân dựa trên các biến độc lập.
- Kiểm định Chi-square (Kiểm định X²): Dùng để xác định sự tương quan giữa các biến định tính.
- Kiểm định Mann-Whitney U: Dùng để so sánh phân phối của hai mẫu độc lập và không giả định phân phối chuẩn.
- Kiểm định Wilcoxon Signed-Rank: Dùng để so sánh phân phối của hai mẫu phụ thuộc.
- Kiểm định Kruskal-Wallis: Dùng để so sánh phân phối của ba hoặc nhiều mẫu độc lập và không giả định phân phối chuẩn.
Những công cụ này cho phép người dùng SPSS thực hiện các phân tích thống kê phức tạp để hiểu rõ hơn về mối quan hệ, sự khác biệt và tương tác trong dữ liệu của họ và đưa ra các kết luận có tính hợp lý.
3. Cách thống kê suy diễn trong SPSS
3.1. Ví dụ cách chạy
Tình huống: Nghiên cứu để so sánh hiệu suất học tập của hai nhóm sinh viên: một nhóm đã tham gia vào một khóa học nâng cao và một nhóm đã không tham gia khóa học đó. Bạn muốn biết liệu có sự khác biệt đáng kể về điểm số trung bình giữa hai nhóm này.
3.2. 4 bước thống kê suy diễn trong SPSS
Để chạy một phân tích thống kê suy diễn cơ bản trong SPSS, bạn có thể làm theo các bước sau đây. Trong ví dụ này, chúng tôi sẽ hướng dẫn bạn cách thực hiện phân tích t-test độc lập (Independent Samples T-Test) để so sánh sự khác biệt giữa hai nhóm.
Bước 1: Mở tệp dữ liệu và chọn biến
Khởi động SPSS và mở tệp dữ liệu chứa thông tin về các biến bạn muốn phân tích.
Chọn biến bạn muốn so sánh giữa hai nhóm. Điều này bao gồm biến của nhóm 1 và biến của nhóm 2.
Ví dụ: bạn có một biến “Điểm số” và một biến “Nhóm” (để chỉ ra nhóm 1 và nhóm 2).
Bước 2: Thực hiện phân tích t-test độc lập
Để thực hiện phân tích t-test độc lập, chọn Analyze từ thanh menu chính, sau đó chọn “Compare Means” và “Independent-Samples T Test”
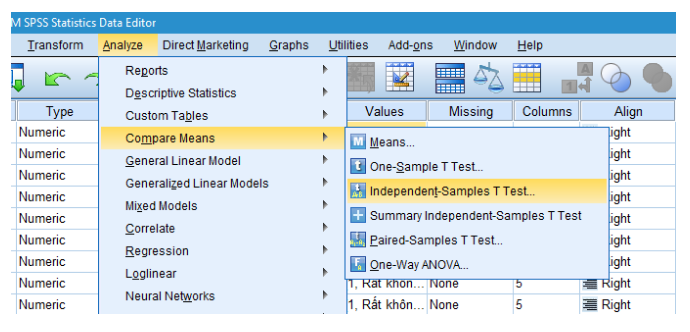
Trong hộp thoại “Independent-Samples T Test,” kéo biến bạn muốn so sánh (ví dụ: “Điểm số”) vào ô “Test Variable(s).”
Trong ô “Grouping Variable,” kéo biến đại diện cho nhóm (ví dụ: “Nhóm”) vào đây.
Ở phần dưới, bạn có thể tùy chỉnh cài đặt phân tích, bao gồm kiểu kiểm định (one-tailed hoặc two-tailed), độ tin cậy, và nhiều tùy chọn khác.
Bước 3: Chạy phân tích
Nhấn nút “OK” để chạy phân tích t-test độc lập.
Bước 4: Xem kết quả
SPSS sẽ tạo một bảng kết quả trong cửa sổ Output. Bạn có thể tìm thấy các thông tin quan trọng như giá trị t-statistic, độ tự do, giá trị p, và ước tính trung bình của từng nhóm. Điều này sẽ giúp bạn đánh giá sự khác biệt giữa hai nhóm.
Chú ý rằng quy trình này chỉ liên quan đến phân tích t-test độc lập. SPSS có khả năng thực hiện nhiều loại phân tích thống kê suy diễn khác nhau, và quy trình cụ thể sẽ thay đổi tùy thuộc vào loại phân tích bạn muốn thực hiện và cấu trúc dữ liệu của bạn.
Sử dụng dịch vụ chạy SPSS có khả năng hỗ trợ bạn trong quá trình thực hiện từ việc tiền xử lý dữ liệu, lựa chọn biến đến việc phân tích kết quả. Điều này giúp tận dụng tối đa các tính năng đặc biệt liên quan đến thống kê suy diễn trong SPSS.
4. Thống kê suy diễn bao gồm các phương pháp nào?
Dưới đây là các phương pháp kiểm định mà thống kê suy diễn sử dụng:
Kiểm định tính phù hợp (Chi-square with one sample):
- Mục đích: Sử dụng để so sánh giá trị của một biến định tính với sự khác biệt.
- Biến đối tượng: Một biến dữ liệu định tính.
Kiểm định tính độc lập (Chi-square with two sample):
- Mục đích: Sử dụng để xác định mối quan hệ hoặc tương tác giữa hai biến định tính.
- Biến đối tượng: Hai biến dữ liệu định tính.
Kiểm định trung bình một mẫu (t-test with one sample):
- Mục đích: Sử dụng để so sánh trung bình của một biến định lượng với một giá trị chuẩn.
- Biến đối tượng: Một biến dữ liệu định lượng.
Kiểm định trung bình hai mẫu độc lập (Independent samples t-test):
- Mục đích: Sử dụng để so sánh trung bình của hai biến.
- Biến đối tượng: Một biến dữ liệu định lượng và một biến dữ liệu định tính với hai giá trị.
Kiểm định trung bình nhiều mẫu (ANOVA test):
- Mục đích: Xác định tác động của nhiều biến độc lập đối với một biến phụ thuộc trong một nghiên cứu hồi quy.
- Biến đối tượng: Hai hoặc nhiều biến độc lập và một biến phụ thuộc.
Kiểm định trung bình hai mẫu phụ thuộc (Dependent samples t-test):
- Mục đích: Kiểm định trung bình của hai biến số được thu thập theo cặp.
- Biến đối tượng: Có hai biến dữ liệu định lượng thu thập theo cặp.
5. Thống kê suy diễn nghiên cứu vấn đề gì?
Thống kê suy diễn nghiên cứu là một phần quan trọng của nghiên cứu khoa học và khoa học dữ liệu. Nó liên quan đến việc sử dụng dữ liệu để đưa ra các kết luận, dự đoán, hoặc suy luận về một vấn đề cụ thể.

Dưới đây là các lĩnh vực mà thống kê suy diễn nghiên cứu có thể được áp dụng:
- Y tế và Dược phẩm: Suy diễn thống kê có thể sử dụng để kiểm tra hiệu quả của một loại thuốc mới bằng cách phân tích dữ liệu từ các thử nghiệm lâm sàng và dự đoán tác động của nó đối với người bệnh trong cộng đồng lớn.
- Kinh tế học: Thống kê suy diễn được sử dụng để phân tích dữ liệu tài chính, dự đoán tăng trưởng kinh tế, và đánh giá tác động của các chính sách kinh tế.
- Môi trường: Nghiên cứu về biến đổi khí hậu và môi trường có thể sử dụng thống kê suy diễn để đánh giá tình hình biến đổi môi trường và dự đoán tác động của nó trên hệ sinh thái và con người.
- Giáo dục: Suy diễn thống kê có thể được sử dụng để đánh giá hiệu suất học tập của học sinh, hiệu quả của các phương pháp giảng dạy, và dự đoán kết quả học tập trong tương lai.
- Kỹ thuật và Công nghệ: Trong lĩnh vực này, thống kê suy diễn có thể được sử dụng để kiểm tra chất lượng sản phẩm, dự đoán sự cố trong quá trình sản xuất, và tối ưu hóa quy trình sản xuất.
- Xã hội học và Khoa học xã hội: Suy diễn thống kê có thể được sử dụng để nghiên cứu các vấn đề xã hội như tình hình kinh tế, giới tính, chất lượng cuộc sống, và thay đổi xã hội.
- Tài chính: Trong lĩnh vực tài chính, thống kê suy diễn được sử dụng để phân tích rủi ro đầu tư, dự đoán giá trị tài sản, và xác định chiến lược đầu tư.
- Chất lượng sản phẩm: Các doanh nghiệp có thể sử dụng thống kê suy diễn để kiểm tra chất lượng sản phẩm và dự đoán sự hài lòng của khách hàng.
Như vậy, thống kê suy diễn nghiên cứu có thể được áp dụng trong nhiều lĩnh vực khác nhau để giúp giải quyết các vấn đề và đưa ra các quyết định dựa trên dữ liệu và suy luận có tính khoa học. Hy vọng bài chia sẻ trên của Luận Văn Việt đã giúp bạn đọc biết cách chạy thống kê suy diễn trong SPSS và nhiều kiến thức hay. Cùng tiếp tục đồng hành với chúng tôi trong những bài viết tiếp theo.

CEO Helen Lưu Hà Chi – Nhà sáng lập website luanvanviet.com , nơi cung cấp các dịch vụ viết thuê luận văn thạc sĩ, tốt nghiệp, tiểu luận, essay, Assignment, cùng với các giải pháp chuyên sâu về xử lý số liệu bao gồm SPSS, STATA, EVIEWS, và SmartPLS.






