
Phân tích nhân tố khám phá EFA là gì? Lấy hệ số tải Factor Loading bao nhiêu mới là đúng? Cách tạo nhân tố và biến đại diện trong SPSS như thế nào? Tất cả những thắc mắc này của bạn sẽ được Luận Văn Việt chuyên dịch vụ SPSS uy tín sẽ giải đáp trong bài viết này.

Giới thiệu phương pháp phân tích nhân tố khám phá EFA
1. Khái niệm nhân tố khám phá EFA
Phân tích nhân tố khám phá EFA là một phương pháp phân tích thống kê dùng để rút gọn một tập gồm nhiều biến quan sát phụ thuộc lẫn nhau thành một tập biến (gọi là các nhân tố) ít hơn để chúng có ý nghĩa hơn nhưng vẫn chứa đựng hầu hết nội dung thông tin của tập biến ban đầu (Hair & ctg, 1998).
Có thể hiểu phân tích nhân tố là tên chung của một nhóm các thủ tục được sử dụng chủ yếu để thu nhỏ và tóm tắt các dữ liệu. Trong nghiên cứu, ta có thể thu thập được một số lượng biến khá lớn. Hầu hết các biến này có liên hệ với nhau và số lượng của chúng phải được giảm bớt xuống đến một số lượng mà chúng ta có thể sử dụng được. Các biến quan sát đưa vào EFA sẽ được rút gọn thành một số nhân tố. Mỗi nhân tố gồm có một số biến quan sát thỏa mãn các điều kiện thống kê.
Đặt tên cho nhân tố EFA
Người phân tích sẽ xem các biến quan sát trong mỗi nhân tố là những biến nào, có ý nghĩa là gì, và cũng cần dựa trên lý thuyết … Từ đó đặt tên cho nhân tố. Tên này cần đại diện được cho các biến quan sát của nhân tố. EFA thường được sử dụng nhiều trong các lĩnh vực quản trị, kinh tế, tâm lý, xã hội học,… Khi đã có được mô hình khái niệm (Conceptual Framework) từ các lý thuyết hay các nghiên cứu trước.
Trong các nghiên cứu về kinh tế, người ta thường sử dụng thang đo scale) chỉ mục bao gồm rất nhiều câu hỏi (biến đo lường). Nhằm đo lường các khái niệm trong mô hình khái niệm, và EFA sẽ góp phần rút gọn một tập gồm rất nhiều biến đo lường thành một số nhân tố. Khi có được một số ít các nhân tố, nếu chúng ta sử dụng các nhân tố này với tư cách là các biến độc lập trong hàm hồi quy bội. Khi đó, mô hình sẽ giảm khả năng vi phạm hiện tượng đa cộng tuyến.
Ngoài ra, các nhân tố được rút ra sau khi thực hiện EFA sẽ có thể được thực hiện trong phân tích hồi quy đa biến (Multivariate Regression Analysis).
Phương trình EFA
Trong EFA, mỗi biến đo lường được biểu diễn như là một tổ hợp tuyến tính của các nhân tố cơ bản. Lượng biến thiên của mỗi biến đo lường được giải thích bởi những nhân tố chung (common factor). Biến thiên chung của các biến đo lường được mô tả bằng một số ít các nhân tố chung cộng với một số nhân tố đặc trưng (unique factor) cho mỗi biến. Nếu các biến đo lường được chuẩn hóa thì mô hình nhân tố được thể hiện bằng phương trình:
Xi = Ai1 * F1 + Ai2 * F2 + Ai3 * F3 + . . .+ Aim * Fm + Vi*Ui
Trong đó,
- Xi : biến đo lường thứ i đã được chuẩn hóa
- Aij: hệ số hồi quy bội đã được chuẩn hóa của nhân tố j đối với biến i
- F1, F2, . . ., Fm: các nhân tố chung
- Vi: hệ số hồi quy chuẩn hóa của nhân tố đặc trưng i đối với biến i
- Ui: nhân tố đặc trưng của biến i
Các nhân tố đặc trưng có tương quan với nhau và tương quan với các nhân tố chung. Bản thân các nhân tố chung cũng có thể được diễn tả như những tổ hợp tuyến tính của các biến đo lường. Điều này được thể hiện thông qua mô hình sau đây:
Fi = Wi1*X1 + Wi2*X2 + Wi3*X3 + . . . + Wik*Xk
Trong đó:
- Fi: ước lượng trị số của nhân tố i
- Wi: quyền số hay trọng số nhân tố(weight or factor scores coefficient)
- k: số biến
Tiêu chuẩn quan trọng trong EFA
- Factor loading phải lớn hơn hoặc bằng 0.5
- Tổng phương sai trích phải lớn hơn 60%
- KMO phải lớn hơn 0.5
- Trong quá trình EFA cần thực hiện phép xoay nhân tố (Varimax hoặc Proximax)
Về mặt ứng dụng, EFA được áp dụng đối với các khái niệm không thể đo lường trực tiếp. Ví dụ như sự hài lòng của khách hàng, hạnh phúc của người Việt Nam. EFA được thực hiện bằng cách gom nhiều biến lại với nhau để tạo thành các nhân tố quan trọng mà chúng ta có thể giải thích được.
2. Nhân tố Factor là gì? Lấy hệ số tải nhân tố Factor Loading bao nhiêu là đúng?
2.1. Nhân tố Factor là gì?
Ý tưởng chính của EFA là các biến có thể quan sát được có một số đặc điểm chung nào đó mà chúng ta lại không thể quan sát trực tiếp.
Ví dụ:
- Nhiều người khi được hỏi các câu hỏi về thu nhập, giáo dục, nghề nghiệp đều có cách trả lời khá giống nhau vì họ có đặc điểm chung về địa vị kinh tế xã hội. Địa vị kinh tế xã hội chính là nhân tố chi phối thu nhập, giáo dục và nghề nghiệp của họ.
Hệ số tải nhân tố càng cao, nghĩa là tương quan giữa biến quan sát đó với nhân tố càng lớn và ngược lại.
Trong phân tích nhân tố khám phá, mỗi nhân tố có chức năng giống như một biến. Nó đo lường phương sai tổng thể của các biến quan sát được và chúng ta thường hay liệt kê theo thứ tự khả năng giải thích của nhân tố đó.
2.2. Lấy hệ số tải nhân tố (Factor Loading) bao nhiêu là đúng?
Theo Hair & ctg (2009,116), Multivariate Data Analysis, 7th Edition thì:
- Factor Loading ở mức ± 0.7: Biến quan sát có ý nghĩa thống kê rất tốt.
- Factor Loading ở mức ± 0.5: Biến quan sát có ý nghĩa thống kê tốt.
- Factor Loading ở mức ± 0.3: Điều kiện tối thiểu để biến quan sát được giữ lại.
Tuy nhiên, giá trị tiêu chuẩn của hệ số tải Factor Loading cần phải phụ thuộc vào kích thước mẫu. Với từng khoảng kích thước mẫu khác nhau, mức trọng số nhân tố để biến quan sát có ý nghĩa thống kê là hoàn toàn khác nhau. Cụ thể, chúng ta sẽ xem bảng dưới đây:

Kích thước mẫu hệ số tải Factor Loading
Trên thực tế áp dụng, việc nhớ từng mức hệ số tải với từng khoảng kích thước mẫu là khá khó khăn. Do vậy
người ta thường lấy hệ số tải 0.45 hoặc 0.5 làm mức tiêu chuẩn với cỡ mẫu từ 120 đến dưới 350.
Lấy tiêu chuẩn hệ số tải là 0.3 với cỡ mẫu từ 350 trở lên.

Ảnh 2 – Hệ số tải Factor Loading
Khi tiến hành thực hiện các tùy chỉnh khi phân tích EFA, tại tùy chọn Options, các bạn tích vào 2 mục:
- Sorted by size: để sắp xếp thứ tự lớn nhỏ hệ số tải trong một nhóm dễ nhìn hơn.
- Suppress absolute values less than: nhập vào giá trị hệ số tải dựa trên cỡ mẫu. Đây là yêu cầu thực hiện lọc các hệ số tải lớn hơn 0.5. Những giá trị nhỏ hơn 0.5 sẽ không hiển thị trên ma trận xoay
Ma trận xoay dưới đây nằm trong bài nghiên cứu có cỡ mẫu 220. Nên mình lấy tiêu chuẩn hệ số tải là 0.5. Tại ma trận xoay, các biến quan sát có hệ số tải <0.5 và các biến quan sát tải lên 2 nhóm nhân tố sẽ bị loại bỏ.

Ảnh 3 – Ma trận xoay
Các biến B5, B7, B6 bị loại do không đảm bảo hệ số tải từ 0.5 trở lên. Biến A7 bị loại bởi không đảm bảo tính phân biệt trong EFA
Lưu ý
Nếu 1 biến tải lên cả 2 nhân tố và đều đảm bảo trên mức hệ số tải tiêu chuẩn. Các bạn cần xem xét rằng 2 giá trị hệ số tải ở 2 nhóm nhân tố có chênh nhau từ 0.3 trở lên hay không. Nếu chênh lệch là lớn >= 0.3 thì biến đó không bị loại và sẽ được xếp vào nhóm có hệ số tải cao hơn. Nếu chênh lệch nhỏ hơn 0.3 thì biến đó bị loại, điển hình là biến A7 ở hình trên. (Nguồn: Nguyễn Đình Thọ, Phương pháp nghiên cứu khoa học trong kinh doanh, NXB Tài chính, Tái bản lần 2, Trang 420)
Trên đây Luận văn Việt đã hướng dẫn bạn cách loại biến khi phân tích nhân tố khám phá EFA dựa trên hệ số tải Factor Loading
Nếu bạn gặp khó khăn trong phân tích nhân tố khám phá EFA, bạn có thể tham khảo dịch vụ xử lý số liệu SPSS của Luận văn Việt. Với kinh nghiệm hơn 20 năm hoạt động trong lĩnh vực này, chúng tôi chắc chắn mang đến chất lượng dịch vụ cũng như giá cả phải chăng nhất cho bạn.
3. Hướng dẫn tạo nhân tố và biến đại diện trong SPSS
Sau khi thực hiện xong phân tích nhân tố khám phá, để tiến hành phân tích tương quan Pearson và xa hơn nữa là hồi quy. Bạn cần tạo các biến đại diện từ kết quả xoay nhân tố cuối cùng.
Bước thực hiện phân tích nhân tố khám phá, khi kết quả phân tích cuối cùng chấm dứt. Các biến quan sát được sắp xếp theo các nhóm nhân tố mới theo 2 tiêu chí: hội tụ và phân biệt. Dưới đây là một ví dụ về ma trận xoay nhân tố hoàn chỉnh:
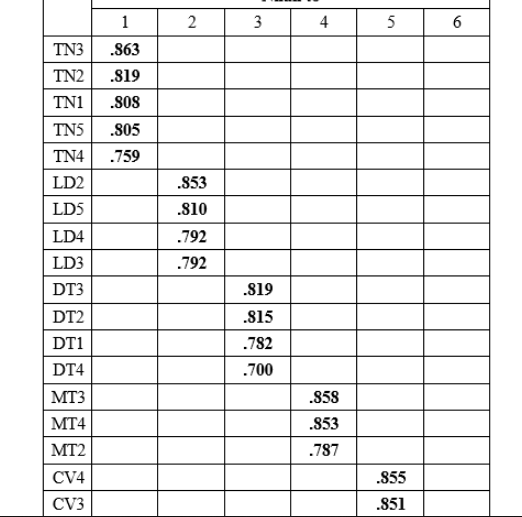
Ảnh 4 – Ma trận xoay nhân tố
Kết quả xoay nhân tố lần cuối chúng ta có được 6 nhân tố mới. Mỗi nhân tố sẽ gồm các biến đại diện nằm chung trên 1 cột. Để tiến hành đánh giá tương quan Pearson và hồi quy, chúng ta sẽ phải tạo các biến đại diện trung bình thông qua lệnh Mean trong Compute Variable.
Ở đây, giả sử bạn tạo lần lượt các biến đại diện là:
- X1 = Mean (TN3, TN2, TN1, TN5, TN4)
- X2 = Mean (LD2, LD5, LD4, LD3)
- …..
- X6 = Mean (DN3, DN4, DN2)
Thực hiện trên SPSS với các bước sau:
Bước 1: Vào thẻ Transform > Compute Variable
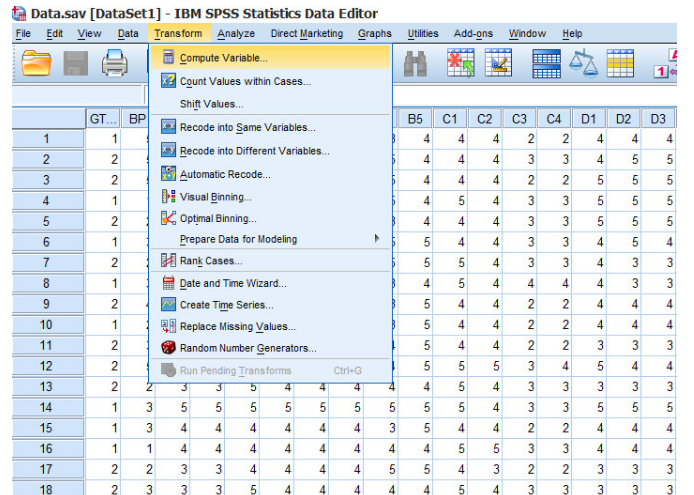
Ảnh 5 – Tạo nhân tố đại diện
Giao diện cửa sổ mới hiện ra như hình dưới. Ở ô Target Variable, các bạn sẽ gõ tên biến đại diện mới (X1, X2, X3….). Mục Type & Label để các bạn điền vào chú thích cho biến, vai trò của nó giống như Lable khi các bạn tạo biến trong cửa sổ giao diện Variable View. Ví dụ biến X1 là đại diện cho nhóm biến quan sát: TN3, TN2….TN4, bạn chú thích biến này là biến Thu nhập thì sẽ gõ vào mục Type & Label.
Bước 2: Gõ cấu trúc hàm vào bảng
Ở ô Numeric Expression các bạn gõ vào cấu trúc hàm: MEAN(TN3,TN2,TN1,TN5,TN4). Nghĩa là tạo biến đại diện X1 là trung bình của các biến quan sát TN3, TN2, TN1, TN5, TN4.

Ảnh 6 – Gõ cấu trúc hàm vào bảng
Bảng kết quả
Sau khi tạo xong, các bạn vào lại giao diện Data View bạn sẽ thấy được các biến đại diện vừa mới được tạo ra bên cạnh các biến quan sát ban đầu:

Ảnh 7 – Bảng kết quả
Như vậy là bạn đã tạo xong các biến đại diện sau khi phân tích EFA để sử dụng các biến này vào phân tích tương quan Pearson và hồi quy về sau.

CEO Helen Lưu Hà Chi – Nhà sáng lập website luanvanviet.com , nơi cung cấp các dịch vụ viết thuê luận văn thạc sĩ, tốt nghiệp, tiểu luận, essay, Assignment, cùng với các giải pháp chuyên sâu về xử lý số liệu bao gồm SPSS, STATA, EVIEWS, và SmartPLS.






